
SQL for Tableau Part 2: Combining Data

Part 1 of our series on SQL for Tableau dealt with the basics. In part 2, we’ll be talking about combining data. Before jumping into the topic, I just want to say that this is a big topic, which includes some of the most critical and powerful SQL functionality you'll use. That being said, this post is a bit lengthy, so be warned.
You can combine data in SQL both horizontally—merging columns from multiple tables—or vertically—adding rows from one table to the rows from another table. To do this we’ll use joins and unions, respectively.
One of the great things about learning joins and unions in SQL is that the concepts are directly applicable to Tableau. In Tableau, you are regularly required to perform both of these operations in order to prepare your data for visualization. So, hopefully the lessons you learn here provide you with an even better understanding of what’s happening in Tableau.
One quick reminder before we jump in—the data we’ll be using is on a publicly available SQL Server database built from the latest Tableau Superstore data. For more details on connecting to the database see Part 1.
Joins
Joins allow you to bring together data from multiple tables and output them in a single result set. For example, our Superstore database contains an Orders table.
SELECT [Order ID], [Customer ID], [Customer Name], [Product ID], [Region], [Sales] FROM [Orders]

We also have a People table:
SELECT [Person], [Region] FROM [People]

We may wish to bring these two tables together so that we can report Orders data along with the Peopledata. To do this, we’ll need to match on the Region field. The goal is to retrieve a single set of records which contains both the order data and the people data, as shown below.
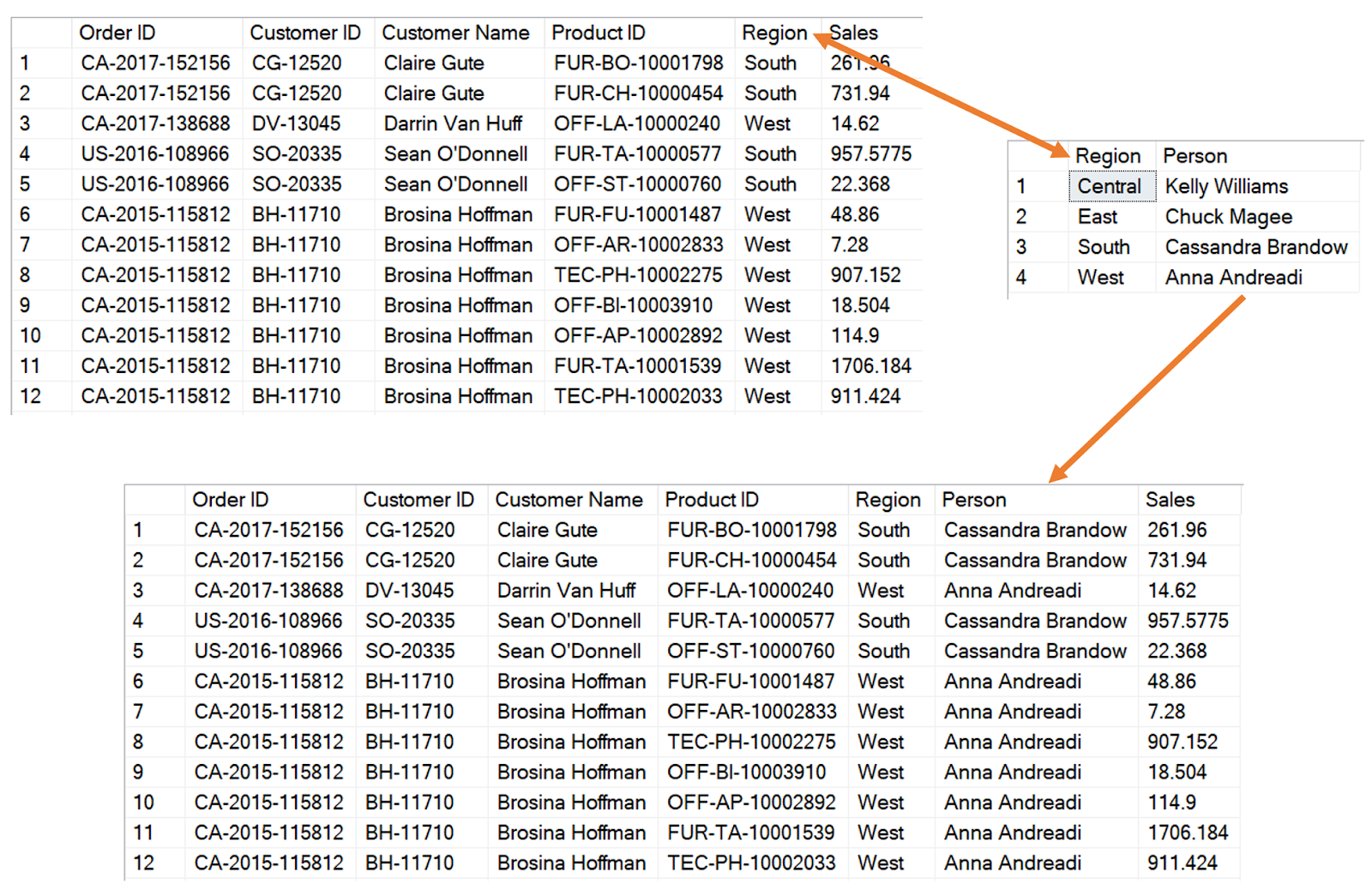
If you’re familiar with Excel, then you’ll know that you can do something similar with a VLOOKUP formula. You’d basically tell Excel that you want to lookup the Person (column 2) from the People sheet, matching on the Region field, as shown below.
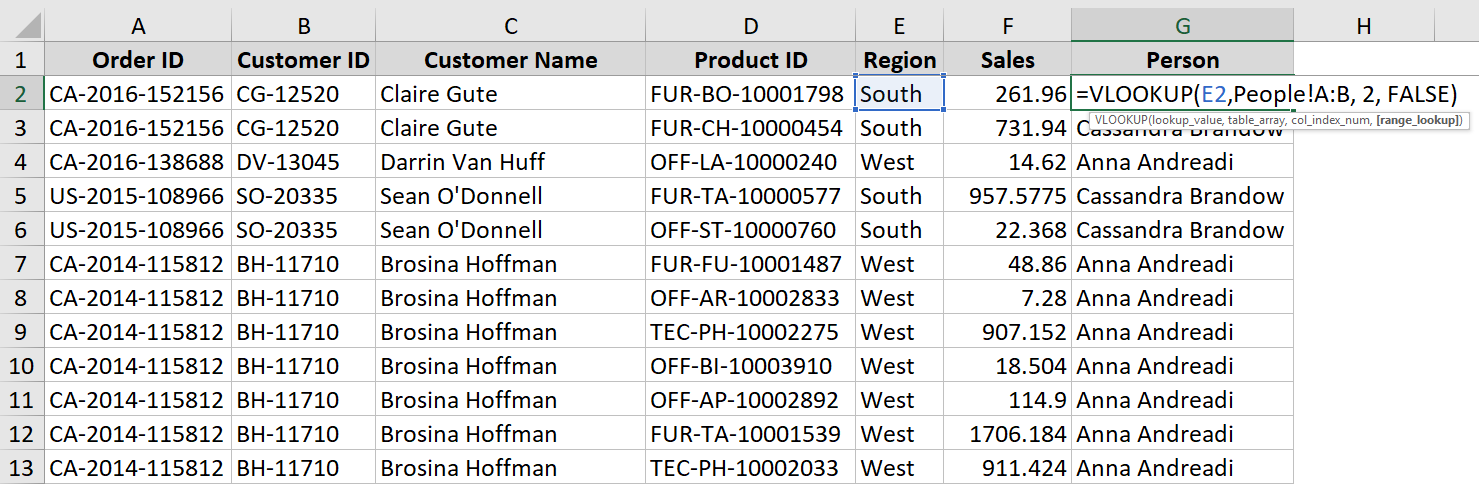
We can do the same basic thing in SQL using a join.
SELECT * FROM [Orders] JOIN [People] ON [Orders].[Region] = [People].[Region]
Let’s break down the syntax a bit. The first part of it is just a normal select statement like we discussed in part 1. Then we add in “JOIN”. This indicates that we are going to perform a join operation between the table in front of the word JOIN, Orders, and the table after JOIN, People. Next, we use ON to indicate the fields we are matching in the two tables. In this case, we are matching Region from Orders to Region from People.
Note: While I won’t show it here, please be aware that the ON clause can contain multiple fields (usually separated by AND) and can contain other expressions such as >=, <>, etc. While a simple = is used most commonly, other operators allow you to do some very creative things with your joins.
Inner Joins
There are a number of different types of joins. The example above uses a simple join (i.e. it only uses the term “JOIN”). Ultimately, this is the same as an INNER JOIN, but just a slightly less verbose option. It is generally considered a best practice to write out INNER JOIN because it reduces confusion when other join types are used. So, the above example might be better written as follows:
SELECT * FROM [Orders] INNER JOIN [People] ON [Orders].[Region] = [People].[Region]
An inner join will return records from both tables only when there is a match on the join clause. The following simple Venn diagram shows how inner joins work.
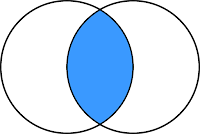
In the above example, any time Region from the Orders table matches Region from the People table, the results will including the matching data from both tables. But if, for example, the “Southeast” region existed in the Orderstable, but not in the People table, then our inner join above would eliminate all orders for the Southeast region.
In the first post, we showed how to can add criteria to your select statement. You can do that with a join as well. For example, we could pull Orders and People data for a specific product category:
SELECT * FROM [Orders] INNER JOIN [People] ON [Orders].[Region] = [People].[Region] WHERE [Category]='Furniture'
Okay, let’s practice!! The Superstore database has a Returnstable which indicates whether or not an order has been returned.
SELECT [Order ID], [Returned] FROM [Returns]

Take a few minutes to write a SQL statement that will return order information along with any related returns…
Got it? Here’s how it would look.
SELECT * FROM [Orders] INNER JOIN [Returns] on [Orders].[Order ID] = [Returns].[Order ID]
But, not every order exists in the Returns table, so this statement will only return orders that exist in both the Orders table and the Returns table.
Outer Joins
Inner joins are the most common and most heavily used join type and will, most likely, be your go to. However, there are more options available to you in case an inner join will not work. Outer joins allow you to retrieve all records from one of your tables even if there is no match in the other table. Let’s take another look at the example discussed earlier where we have orders for the Southeast region in our Orders table, but the Peopletable does not contain this region. If we wish to make sure that we pull all of the records from the Orders table, regardless of whether or not they exist in the People table, we can use an outer join as follows.
SELECT * FROM [Orders] LEFT OUTER JOIN [People] ON [Orders].[Region] = [People].[Region]
The “LEFT” here simply indicates that the table on the leftside of the join (Orders) is the table from which we’re retrieving all records. If we wanted to do the opposite and retrieve all records from Peopleand only those that match from Orders, then we could either use a rightouter join:
SELECT * FROM [Orders] RIGHT OUTER JOIN [People] ON [Orders].[Region] = [People].[Region]
Or we could change the position of the tables and continue using a left outer join:
SELECT * FROM [People] LEFT OUTER JOIN [Orders] ON [Orders].[Region] = [People].[Region]
When changing the position of the tables, you might be tempted to change the position of the join criteria as follows:
SELECT * FROM [People] LEFT OUTER JOIN [Orders] ON [People].[Region] = [Orders].[Region]
But this is not necessary—SQL does not care about the order of the fields in the “ON” clause as long as they evaluate, as a whole, to a Boolean (True or False).
So, left and right joins are basically the same thing—the "left" and "right" simply indicate which of the tables is the primary. Again, here are Venn diagrams showing how left and right outer joins work:

Like the INNER JOIN example, “LEFT OUTER JOIN” and “RIGHT OUTER JOIN” can be simplified syntactically to “LEFT JOIN” or “RIGHT JOIN” but I personally feel it’s better style to include the “OUTER” keyword so as to delineate between inner and outer joins.
Full Outer
Full outer joins are a type of outer join that essentially combines both a left join and a right join.

Here's an example:
SELECT * FROM [People] FULL OUTER JOIN [Orders] ON [Orders].[Region] = [People].[Region]
This will give us all records from People, even when there is no match in Orders (if no match, the fields from Orders will be NULL) plus it will give us all records from Orders, even if there is no match in People (if no match, then the fields from People will be NULL).
Note: Like other join types, the syntax can be simplified to “FULL JOIN”.
I’ll take a moment here to say that full outer joins are very uncommon. There are some use cases, such as certain types of exception reporting, but ultimately they’re pretty rare.
Cross Join
Cross joins are another less common join type. They will join each record from one table to each record from another. The Superstore data set doesn’t have many good use cases for cross joins, so I’ve created two new tables in our database, Shapes and Colors.
SELECT * FROM [Shapes]

SELECT * FROM [Colors]

As you can see, we have four shapes and three colors. What if we wanted to determine all the possible combinations of shapes and colors? We can accomplish this using a cross join as follows:
SELECT * FROM [Shapes] CROSS JOIN [Colors]

As you can see, our output combines each record in Shapes with each record in Colors, creating a total of 12 records—each possible combination.
While this may seem like a strange thing to do, it’s actually relatively common in Tableau. It can be particularly valuable when you are trying to perform some type of data densification (if you are unfamiliar with data densification, I highly recommend Joe Mako’s video tutorial on the topic).
Take for example, the sankey template available on my website, based on the work of Olivier Catherin and Jeffrey Shaffer. The Excel template contains one tab for our “model” which contains 98 records needed to help calculate our curves. Each record in the model has a field called “Link” with a value of “link” in each record.

Another tab contains our aggregated data and also includes the “Link” field.

In Tableau, we join based on this field.
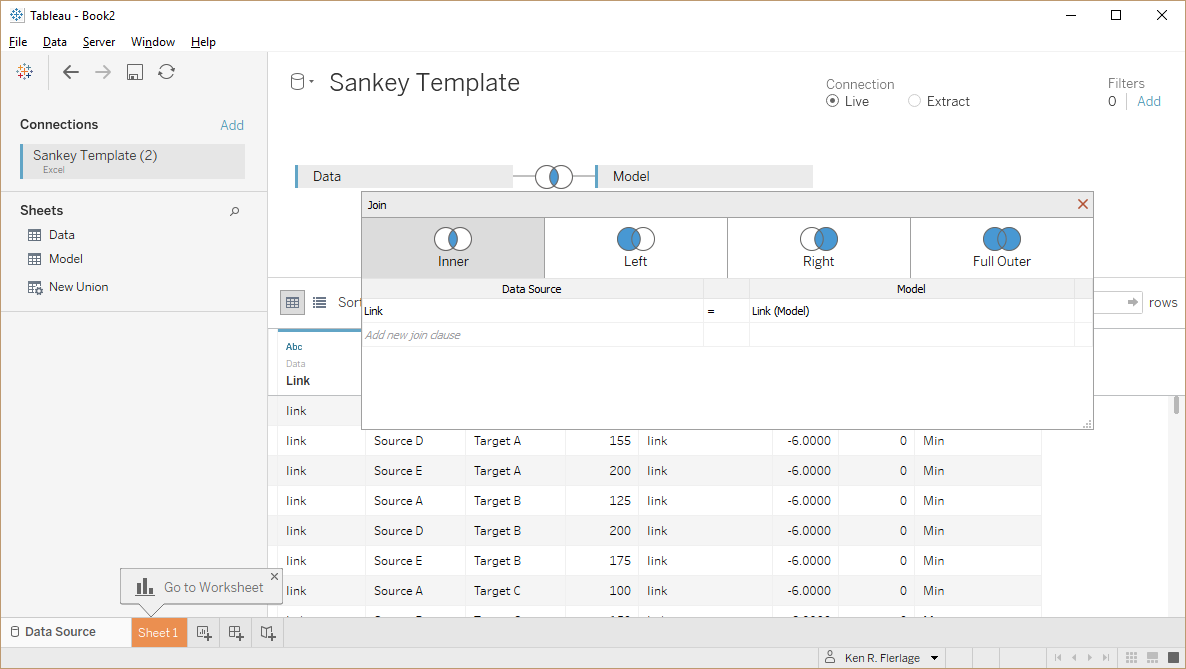
The end result is that each record in the Data table gets combined with each record in the Modeltable, allowing us to properly densify our data in order to draw the curves. While this is technically an inner join based on the Link column, we are pretty much doing the same thing as a cross join. Since Tableau doesn’t support cross-joins out of the box, we’re using this “Link” field as a sort of workaround. Cool huh?
Note: Like we've done in Tableau, we can also use an inner join in SQL to mimic a cross join by doing something like this:
Or, more commonly, people will simply use the value 1, as follows:
Note: Like we've done in Tableau, we can also use an inner join in SQL to mimic a cross join by doing something like this:
SELECT * FROM [Data] INNER JOIN [Model] ON 'Link' = 'Link'
Or, more commonly, people will simply use the value 1, as follows:
SELECT * FROM [Data] INNER JOIN [Model] ON 1 = 1
Table Aliases
The examples provided above are quite simple, but the syntax of joins can be a bit tricky. For starters, the examples all use “SELECT *” which will retrieve all columns from both tables in the join. As noted in the first post, this puts a lot of extra strain on the database engine and should be avoided. Instead, you’ll want to explicitly specify the column names you wish to retrieve. For example:
SELECT [Order ID], [Order Date], [Product ID], [Category], [Region], [Person] FROM [Orders] LEFT OUTER JOIN [People] ON [Orders].[Region] = [People].[Region]
In this case, we’ve stated each individual field we wish to return. But…if you run this, you’ll receive the following error (or something similar, depending on the database platform):
Ambiguous column name 'Region'
This means that one of the columns we’ve used exists in both of our join tables. In our case, that column is Region. So, we’ll need to adjust our syntax to explicitly state the table from which we want to retrieve the Region field. We can do that as follows:
SELECT [Order ID], [Order Date], [Product ID], [Category], [Orders].[Region], [Person] FROM [Orders] LEFT OUTER JOIN [People] ON [Orders].[Region] = [People].[Region]
In general, it is good practice to prefix all of the columns with the table name so that there is no confusion.
SELECT [Orders].[Order ID], [Orders].[Order Date], [Orders].[Product ID], [Orders].[Category], [Orders].[Region], [People].[Person] FROM [Orders] LEFT OUTER JOIN [People] ON [Orders].[Region] = [People].[Region]
As you can see, however, this can start to create very long SQL statements. This example is not too bad, but let’s imagine, for a moment, that we are retrieving many more of our fields and that our table names are significantly longer—for example, perhaps “Orders” is actually “Customer_Sales_Order_Table” and “People” is actually “Regional_Sales_People”. A resulting SQL might look like this:
SELECT [Customer_Sales_Order_Table].[Row ID], [Customer_Sales_Order_Table].[Order ID], [Customer_Sales_Order_Table].[Order Date], [Customer_Sales_Order_Table].[Ship Date], [Customer_Sales_Order_Table].[Ship Mode], [Customer_Sales_Order_Table].[Customer ID], [Customer_Sales_Order_Table].[Customer Name], [Customer_Sales_Order_Table].[Segment], [Customer_Sales_Order_Table].[Country], [Customer_Sales_Order_Table].[City], [Customer_Sales_Order_Table].[State], [Customer_Sales_Order_Table].[Postal Code], [Customer_Sales_Order_Table].[Region], [Customer_Sales_Order_Table].[Product ID], [Customer_Sales_Order_Table].[Category], [Customer_Sales_Order_Table].[Sub-Category], [Customer_Sales_Order_Table].[Product Name], [Customer_Sales_Order_Table].[Sales], [Customer_Sales_Order_Table].[Quantity], [Customer_Sales_Order_Table].[Discount], [Customer_Sales_Order_Table].[Profit], [Regional_Sales_People].[Person]
FROM [Customer_Sales_Order_Table] LEFT OUTER JOIN [Regional_Sales_People] ON [Customer_Sales_Order_Table].[Region] = [Regional_Sales_People].[Region]
Now our SQL is starting to get very long. While there’s nothing wrong with that, we might wish to make this a little simpler by using table aliases. To create a table alias, you use the “AS” clause after your table name (Note: This is similar to the use of “AS” to alias a column name, as described in the first post). For instance, let’s add some aliases to the following:
SELECT * FROM [Orders] LEFT OUTER JOIN [People] ON [Orders].[Region] = [People].[Region]
We can alias the Orders and People tables as follows:
SELECT * FROM [Orders] AS O LEFT OUTER JOIN [People] AS P ON O.[Region] = P.[Region]
Notice that, when we do this, we must then use that alias as the table names in our “ON” statement. The same goes for the list of columns we retrieve. For example:
SELECT O.[Order ID], O.[Order Date], O.[Product ID], O.[Category], O.[Region], P.[Person] FROM [Orders] AS O LEFT OUTER JOIN [People] AS P ON O.[Region] = P.[Region]
Note: Aliases can be useful for many other things than just simplifying your SQL, but I won’t be going into any further detail here.
Joining Multiple Tables
Joins can include more than just 2 tables. In fact, the number of tables you can join is virtually limitless. The Superstore database, unfortunately, doesn’t have enough tables to properly demonstrate this, so I’ve created an additional Customers table to use in the following example. The SQL below joins Orders, People, and Customers together.
SELECT O.[Order ID], O.[Order Date], O.[Product ID], O.[Category], O.[Region], P.[Person], C.[Customer Name] FROM [Orders] AS O INNER JOIN [People] AS P ON O.[Region] = P.[Region] INNER JOIN [Customers] as C on O.[Customer ID]=C.[Customer ID]
While this example uses two inner joins, you can mix and match join types within a single SQL statement in order to meet your specific needs.
Beware of Data Duplication
Because joins will match fields in one table to fields in another table, there is the potential that you could inadvertently duplicate records. The Superstore data set is too well-structured to allow for this, but I’ve created a new table called PeopleMultiplewhich can contain multiple sales people for each region. For example, we can see below that the table contains two people for the West region, Anna Andreadi and Willy Wonka.
SELECT * FROM [PeopleMultiple]

So, if we join a table to PeopleMultiple based on the region field, we may end up duplicating our data. To demonstrate, let’s look at the order with Row ID 6288.
SELECT [Row ID], [Region] FROM [Orders] WHERE [Row ID]=6288

As we can see, there is only one record in the Orders table. But, what happens if we join to PeopleMultiple based on the region?
SELECT [Orders].[Row ID], [Orders].[Region], [PeopleMultiple].[Person] FROM [Orders] INNER JOIN [PeopleMultiple] ON [Orders].[Region] = [PeopleMultiple].[Region] WHERE [Orders].[Row ID]=6288 ORDER BY [Row ID], [Person]

Because our People table contains multiple sales people for the West region, our one order record joins to both People records, resulting in two records. In some cases, you may want this, but in others you may not. If you did not want this to happen and pulled this data into Tableau, you may inadvertently overstate the sales for the West region by 2x, which could cause you some major problems. So, be careful and be sure that you have a good understanding of your data before you start performing your joins.
Union
While joins allow us to combine data in a horizontal fashion, unions allow us to combine data in a vertical fashion. Take for example these two very simple tables:
SELECT * FROM [Charts1]

SELECT * FROM [Charts2]

We may wish to merge these two tables into a single result set, as follows:
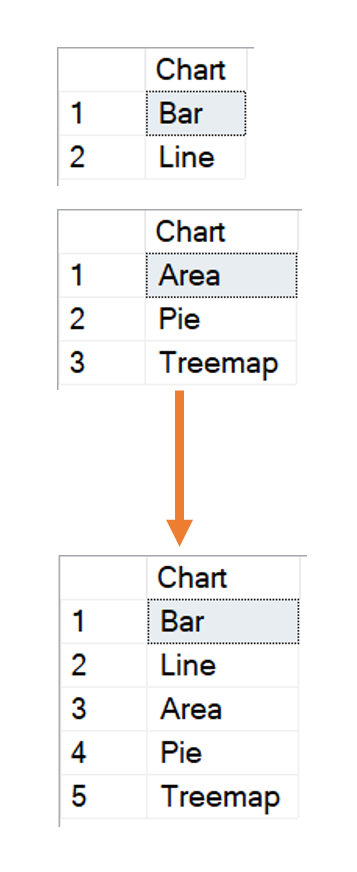
For this, we can use a UNION.
SELECT * FROM [Charts1]
UNION
SELECT * FROM [Charts2]
Let’s look at another example. Because the Superstore data doesn’t include many union use cases, I’ve created four separate tables, each showing orders for a specific region. Let’s say that we wish to merge the orders for the Central and East regions. We can do the following:
SELECT * FROM [Orders_Central]
UNION
SELECT * FROM [Orders_East]
This example shows two tables, but it can include as many as you like. For instance:
SELECT * FROM [Orders_Central]
UNION
SELECT * FROM [Orders_East]
UNION
SELECT * FROM [Orders_West]
Notice the use of SELECT * in this case. This works here because each of the three tables have the exact same structure—the same number of columns, same column names, same column data types, etc. In order for a union to work, the columns from each select statement must have the exact same structure. To demonstrate this further, I created the Orders_Southtable with a different number of columns and different field names. If we try to union it with the above, we’ll get an error. So, we’ll need to use some column aliases to ensure that our columns match in all four tables.
SELECT [Order ID], [Order Date], [Product ID], [Sales] FROM [Orders_Central]
UNION
SELECT [Order ID], [Order Date], [Product ID], [Sales] FROM [Orders_East]
UNION
SELECT [Order ID], [Order Date], [Product ID], [Sales] FROM [Orders_West]
UNION
SELECT [ID] AS [Order ID], [Date] AS [Order Date], [Product] AS [Product ID], [Amount] AS [Sales] FROM [Orders_South]
With all four columns matching in both name and type, this SQL will now produce the expected results.
UNION vs UNION ALL
There are two variants of UNION—the regular union we’ve used above and UNION ALL. UNIONwill attempt to retrieve a distinct list of records from the tables. So, if both the tables in our union have the exact same record, then UNION will merge those into a single record. UNION ALL operates in a much less intelligent manner—it will simply combine both sets of records, without attempting to remove duplicates. Take, for example, the following SQL, which attempts to union the full Orders table to the orders for the Central region. Note: The Orders table has 9,994 records, while the Central table has 2,323.
SELECT * FROM [Orders]
UNION
SELECT * From [Orders_Central]
Since every record in Orders_Central already exists in Orders, the records from the second table are essentially eliminated because they are duplicates. Thus, this query will return just 9,994 records.
But, using UNION ALL will produce different results.
SELECT * FROM [Orders]
UNION ALL
SELECT * From [Orders_Central]
Because UNION ALL does not care about duplicates, the result of this query will be 12,317 records (9,994 + 2,323).
They key driver in when to use one vs the other comes down to your use case. In many cases, you will know ahead of time that there are no duplicates in the tables you are trying to union. If you know this, then use UNION ALL instead of UNION. Because UNION ALL does not attempt to eliminate duplicates, the database has much less work to do to retrieve your result set. Thus, UNION ALL queries are significantly more performant than regular unions. If duplicate records are likely and you wish to eliminate those duplicates, then a UNION will be more appropriate.
Coming Up…
That was a long one! Thanks for reading. I hope you learned something new. In part 3 of this series (hopefully coming in another 2 weeks or so), we’ll be talking about aggregation.
Ken Flerlage, September 15, 2018























Another nice job of explaining some basic concepts that can be complex to understand!
ReplyDeleteThank you, Laura!
DeleteHi Ken! Thanks for this SQL blog series. One question, when inner-joinning multiple data sets, does the order of the join matters for the end result? Thanks!
ReplyDeletePS: I'm Adolfo
Hey Adolfo. No, the order of inner joins do not matter, but it starts to get really tricky when you're doing outer joins. In that case, the order is important and it can also be very very confusing.
DeleteAh, thanks. I guess I didn't even realize that SSMS isn't available for Mac. C'mon Microsoft!!
ReplyDeleteA BIG THANKS! for the Awesome article Ken. Well articulated! I worked out while i gave a read to this. This is Awesome! Thanks once again, Ken!
ReplyDeleteI believe that the Orders table does not appear to have any region "southeast" entries, making the outer join example a bit hard to follow. That said, I very much appreciate this blog! Nice tutorial, just what I was looking for.
ReplyDeleteKen! Wow, thank you very much for sharing your deep knowledge.
ReplyDeleteYour blog post is better than most paid courses.
Thanks for the kind words!
DeleteHi Ken,
ReplyDeleteI just wanted to say how well laid out these overviews are, and how useful. I'm in an Policy Officer post at an HE institution in the UK which involves MI and our dept has recently started training on Tableau. This is clearing a lot up for me!
Thanks very much
Ali
That's good to hear!! :)
DeleteSo can you write SQL queries in Tableau? Or is this a thing of the past? My boss is baffled that Tableau doesn't have the capability. I'm trying to communicate that Tableau can connect to custom queries, locally or stored on a server, can connect to databases, but not write and edit the SQL code. Is my understanding correct? How do I tell her that this is a normal thing about Tableau?
ReplyDeleteThank you
As long as your source supports SQL (i.e. a "real" database--not Excel, csv, etc.) then yes you can use the "Custom SQL" option to write your own SQL. See https://help.tableau.com/current/pro/desktop/en-us/customsql.htm
DeleteSo does Tableau's Union feature act like the SQL Union or the SQL Union All ?
ReplyDeleteTableau performs a UNION ALL.
Delete